باکو پایتخت جمهوری آذربایجان، شرقی ترین پایتخت قاره اروپا و بزرگترین شهر و همچنین بزرگترین…

آیا واقعا گوگل از ترجمههای ترگمان استفاده میکنه؟
حتما شما هم بمب خبری استفاده گوگل از ترگمان که تو این چند روز خیلی سروصدا کرده رو شنیدهاید. احتمالا سوالات زیادی ذهنتون رو مشغول کرده. خوندن رو ادامه بدید که سعی کردیم تو این پست بلاگ به تمام سوالاتون جواب بدیم.
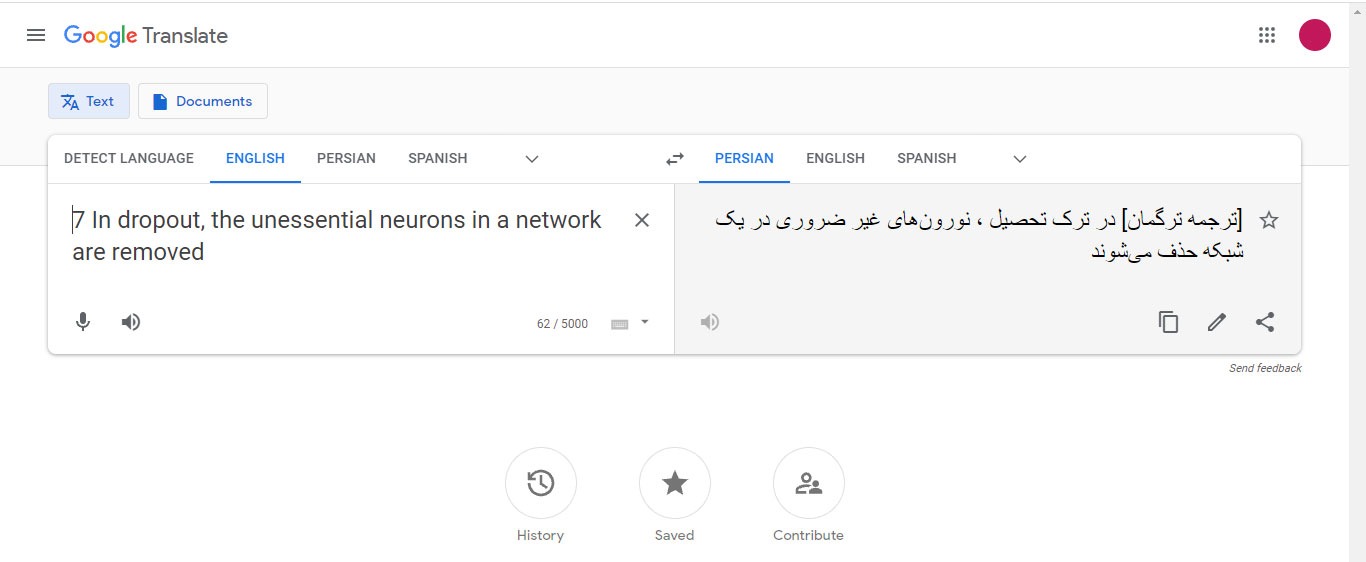
چند روز پیش یکی از کاربران توییتر یک توییتی مبنی بر اینکه گوگل ترنسلیت داره تو ترجمههاش از ترجمه ترگمان استفاده میکنه رو توییت کرد. این توییت بازخوردهای زیادی رو تو شبکههای اجتماعی توییتر، اینستاگرام، تلگرام و … به دنبال داشت. بسیاری از کاربران این عبارت رو در گوگل ترنسلیت وارد کردند و صحت این خبر رو بررسی کردند (پیشنهاد میکنیم شما هم عبارت ۷ In dropout, the unessential neurons in a network are removed. رو در گوگلترنسلیت بزنید و نتیجهاش رو حتما ببینید!).
قصه از کجا شروع شد؟
تقریبا از دو سال قبل زمانی که بچههای ترگمان برای بررسی خروجیهای ترجمیار که در حال حاضر هم برای ترجمه خلاصه مقالات در فریپیپر استفاده میشه، تعدادی از جملاتی که گنگ و اشتباه ترجمه شده بودند رو در گوگل قرار دادند متوجه موضوع جالبی شدند. گوگل عینا همون ترجمهها رو بدون هیچ تغییری و به غلط ارائه داد!
اولین تئوری که مطرح بود این بود که ترگمان و گوگل از پیکرههای مشابهی که در سرتاسر وب وجود داره، استفاده میکنند. اما با بررسیهای دقیقتر مشخص شد که سرچشمه این خطاها به پیکره اختصاصی ترجمیار و حیطه تخصصی اون برمیگرده و در وب قابل دستیابی نبود!
اینجا بود که این تئوری که گوگل موتورهای ترجمهاش رو با استفاده از ترگمان و ترجمیار آموزش میده قوت گرفت. اما از اونجایی با مطرح کردن این ماجرا ترگمان متهم به استفاده از گوگل میشد (یعنی دقیقا عکس ماجرا)، تعمدی خطاهایی با امضای ترگمان در ترجمهها گنجونده شد تا در آینده قابل پیگیری باشن.
تو این مدت خیلی بررسیها شد و نشانههایی هم پیدا شد اما قابل پیگری و اثبات نبودند. تا اینکه در چند روز گذشته بالاخره گوگل دست خودشو رو کرد! جملهای که به خطا و البته از قصد با امضای ترگمان در پیکره گنجونده شده بود رو گوگل ارائه کرد.
نقطه اشتراک مترجمهای ماشینی جدید، استفاده از الگوریتمهای یادگیری عمیق هست. در واقع این مترجمها ارتباطی میان دادههایی که بهشون داده میشه رو پیدا میکنن و خودشون رو به نوعی آموزش میدن. و از اونجایی که بیشتر این موتورها از الگوریتمهای یادگیری مشابهی استفاده میکنن، برتری این موتورها به میزان دسترسی و کیفیت متنهای ترجمهشدهای هست که به اونها داده میشه.
اگر میخواید با زوایای فنی این ماجرا آشنا بشید پیشنهاد میکنم مقاله مهران ضیابری، مدیرعامل ترگمان، رو در مورد استفاده گوگل از ترگمان بخونید.
امکان ارائه این ترجمه از سمت بچههای ترگمان به گوگل هست؟
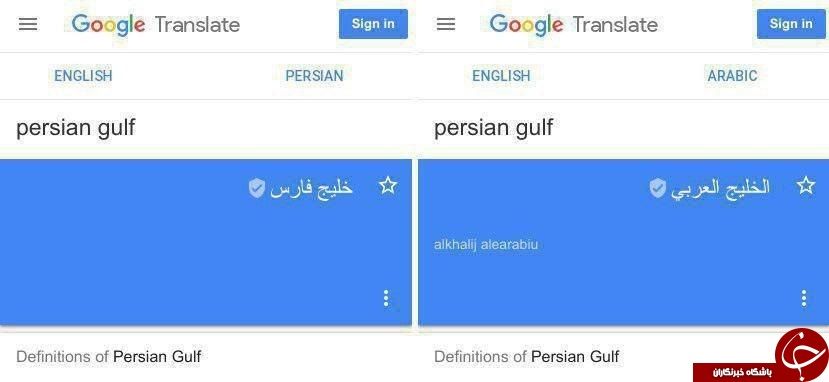
در این مرحله هست که بعضی از دوستان غریبنواز میگن که احتمالا خود بچههای ترگمان پیشنهاد این ترجمه رو به گوگل ارائه دادند! پس اینجا جا داره که این نکته رو یادآوری کنیم که گوگل بعد از جنجال ترجمه کلمه «احمدینژاد»، «خلیج فارس» و موارد دیگهای در دیگر زبانها رویهاش رو تغییر داد. یعنی دیگه هیچ ترجمه پیشنهاد شده توسط کاربران رو مستقیما در موتور وارد نکرد. و برای اون دسته از ترجمههایی که توسط کاربران تایید شده بودند یک تیک رو جلوی ترجمه نمایش میده.
کلام آخر
برای ما موجب افتخار هست که یک محصول ایرانی با وجود تمام محدودیتها و مشکلات تونسته در عرصه بینالمللی رقابت پایاپایی رو با کمپانی بزرگی مثل گوگل داشته باشه. قطعا ترگمان هیچوقت ادعای برتری بر سایر سرویسها رو نداشته اما همیشه تمام تلاش خودش رو برای پیشرفت و ارائه کیفیت مطلوب ارائه داده. امیدواریم در آینده نه چندان دور سرویسهای ترگمان و ترجمیار که در APIهای فریپیپر هم استفاده میشن، حرف اول رو از نظر سطح کیفی بزنند.
Related Posts


